
Attention is all you need
Attention is all you need
Attention is all you need
structure
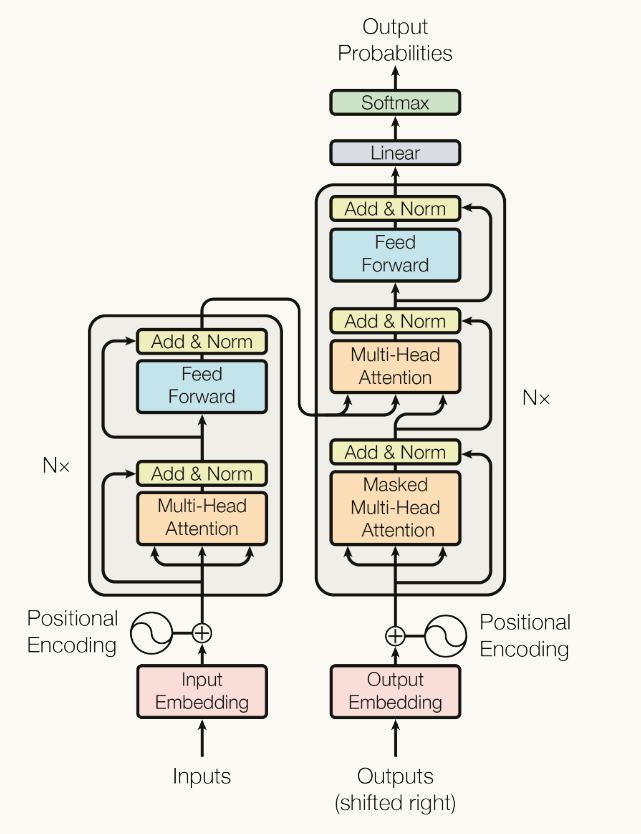
Encoder and decoder
Encoder
编码器由6层组成,每层包含两个子层(多头注意力层,全连接网络层)在每层后使用残差连接和层归一化
残差连接类似一种兜底策略,目的是使得 就算模型的深度已经达到最优解,后面再增加冗余层也至少不会导致之前的效果下降 。
Decoder
同样由6层组成,但每层包含三个子层(增加了一个掩码多头注意力层)目的是为了防止当前位置注意到后续的位置。
Attention
$$
\mathrm{Attention}(Q,K,V)=\mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V
$$
Q,K,V均来自于输入的特征的线性变换
其中Q代表着需要查询的信息,K代表着输入本身的内容,V代表着原本的信息。
所以如果不引入注意力机制,全部使用V就是简单的全连接神经网络
Q和K的乘积表示了需要的内容和本身的内容之间的相似度,进而指出了需要注意哪些内容
比例系数是为了防止softmax后的值过大,所有的注意力被分走,同时可以让softmax的偏导数不至于太小,加快收敛速度
Multi-Head Attention
$$
\text{MultiHead}(Q, K, V) = \text{Concat(head}_1, …, \text{head}_h)W^O
$$
$$
\text{where head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
$$
将输入的dk维度,分成h个头来分别执行注意力操作 再将其拼接起来 这样做可以允许模型从不同的子空间关注不同的位置
FFN
作用是引入非线性变换增强模型的学习能力? 混合多头注意力处理的结果? 给模型一个思考的空间来处理注意力计算的结果? 在记忆方面有作用?
作用目前尚没有定论 有很多说法


Related Articles


